DeepTracking: Real-Time Object Tracking

Introduction
DeepTracking is a comprehensive study in which we demonstrate the effects of different architectures on the original GOTURN model [1]. The tracker’s objective is to understand shape, motion, appearance changes of objects over variant periods of time, and keep track of the object location throughout a sequence of frames. To achieve that, we have lots of factors (i.e. accuracy, robustness, runtime/fps, memory footprint, training time) to fine-tune to reach the optimal objective.
In this project, we show that parallel latent fully connected layers could achieve better results (in terms of accuracy and robustness) than the original GOTURN model in a significantly lower number of training iterations. The downside is a slight decrease in runtime and an increase in memory footprint.
This research project was held as a final project for the Deep Learning for Computer Vision graduate class at the Technical University of Munich (TUM) under the supervision of Prof. Dr. Laura Leal-Taixé and Prof. Dr. Matthias Nießner.
Datasets
We follow the GOTURN’s training approach [1]. We train our network on two datasets:
- ALOV++: That consists of 314 videos, 251 different objects and each has 52 frames on average. The network trains on approximately 13000 frames.
- ImageNet Detection: It contains around 47GB worth of images with bounding boxes. We stochastically select bounding boxes and generate sequences of non-moving objects.
For testing, we are benchmarking against VOT2014 dataset [2].
Training
We use stochastic gradient descent with batch size 50. Each item in the batch represent two consecutive frames. Each batch contains 25 sequences from ALOV++ and 25 others that come from ImageNet detection dataset (i.e. these are non-moving objects).
Biases are initialized to ones. Weights are normally distributed with mean zero, and standard deviation 0.003. Learning rate is generally set to 10^-6. However, weights have 10 times that rate. And, biases have 20 times that rate. The same motion smoothness model from GOTURN was used.
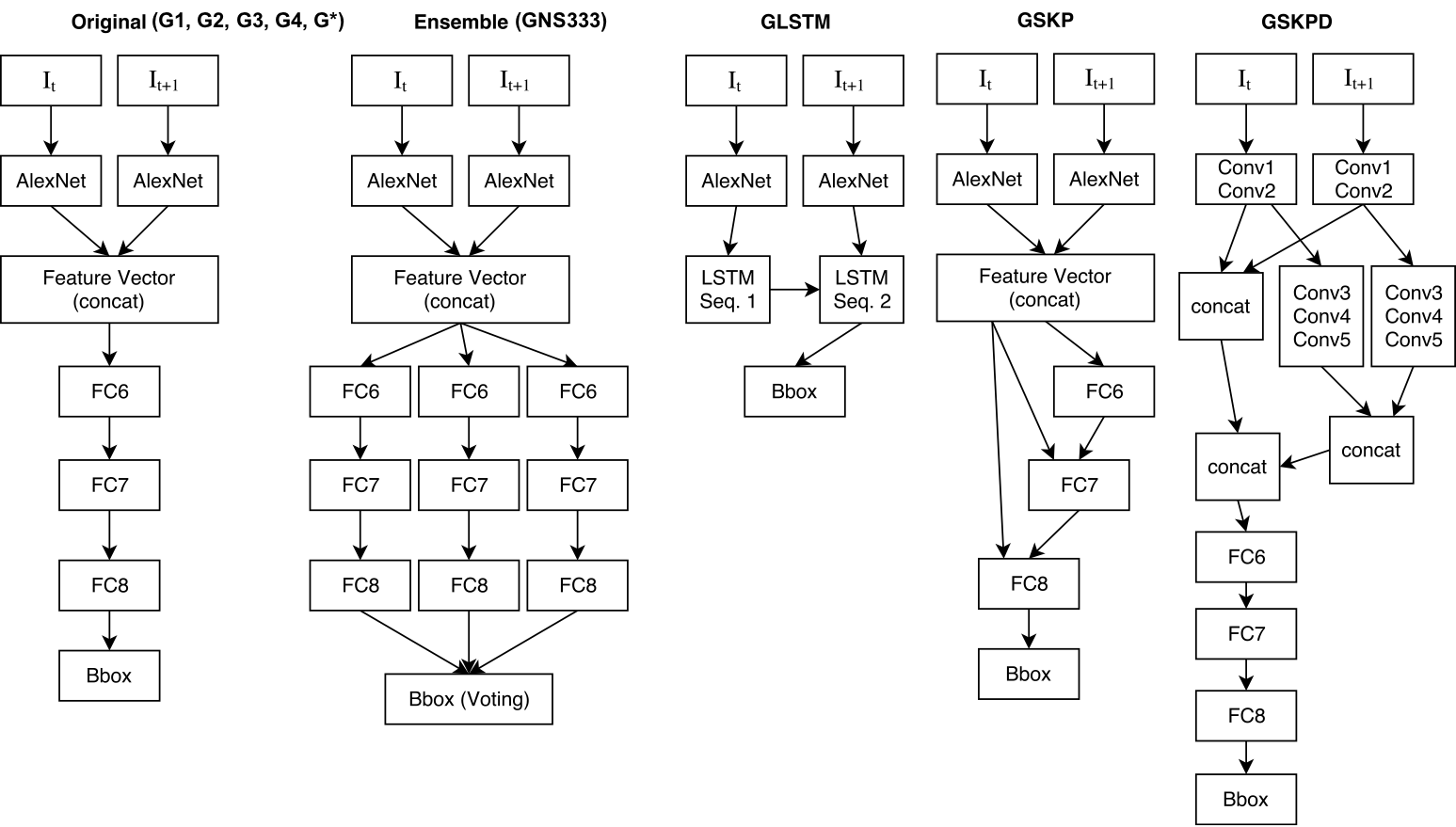
Methodology
- G1, G2, G3, G4 and G* have 3x fully connected Layers. Each has 4096 neurons.
- GFC1, GFC2 removes 2 and 1 fully connected layers, respectively.
- GVGG16 only replaces AlexNet with VGG16 as feature extractors.
- GLSTM has one LSTM layer with 2048 neurons.
- In both GNS321 and GNS333, we trained the models independently and later transferred the weights to produce the ensemble.
Experimental Results

Analysis
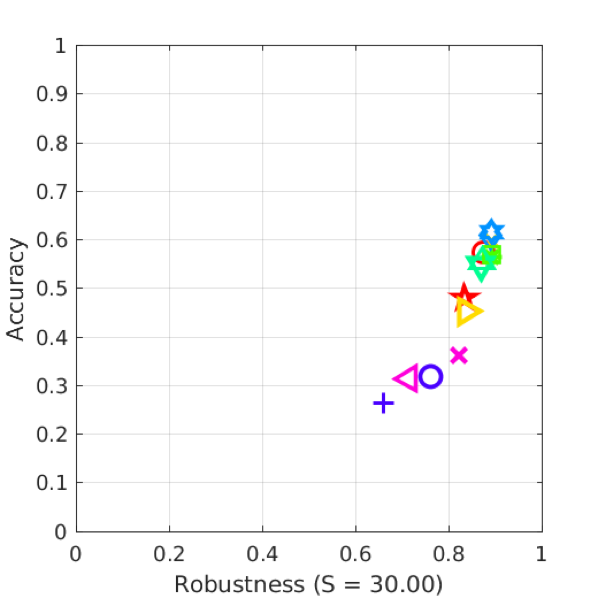
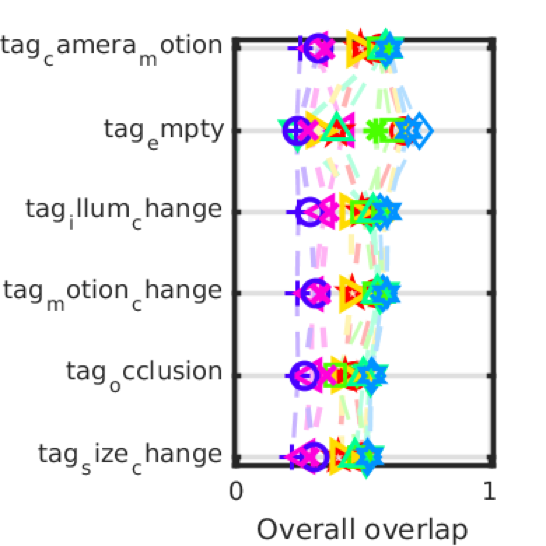
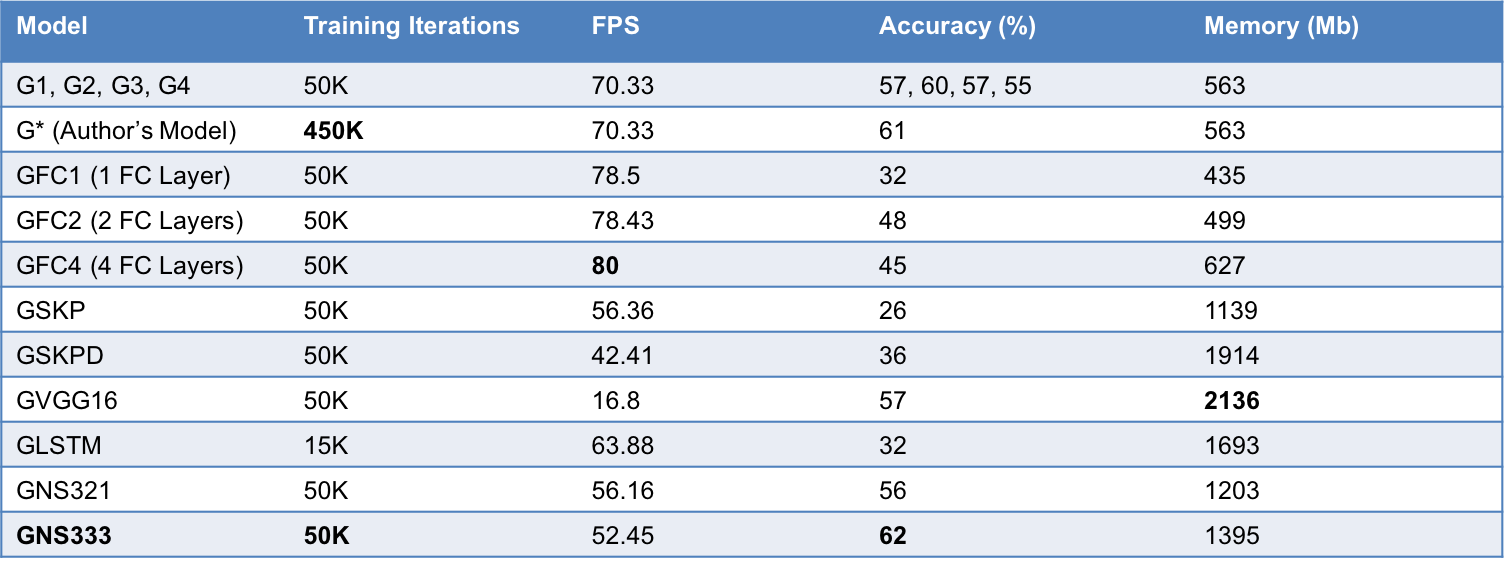
While benchmarking our architectures, we used the VOT competition toolkit to evaluate our results on the VOT2014 dataset. Our best model is an ensemble of fully connected layers. We trained three GOTURN models for 50K iterations. After that, we benchmarked each model against VOT2014. We used the accuracy as weights in the ensemble voting. Finally, we created a new model with 3 parallel fully connected layers as shown in the graph. Finally, we transferred the weights to the new model from the three previously trained models. That yield in a model that was trained for 50K iterations and achieved better results (i.e. accuracy and robustness) than the Author’s model that was trained for 450K iterations. We also found the following:
- In the first 50K iterations, both AlexNet and VGG16 features achieve very similar accuracy. VGG16 features are more robust. However, VGG16 is 4.3 times slower than AlexNet with 10 million more parameters. If trained longer, we believe VGG16-based tracker will outperform the original AlexNet-based one.
- Models with skip connections converge slower than the original model. Combining features and fully connected outputs performs poorer than combining features together. Skip connections yield in massive feature vectors that make it harder for the model to converge in the same time. If trained longer, it might have achieved better accuracy.
- As illustrated in [1], more fully connected layers yield in higher accuracy till they over-fit. 4 fully connected layers converge much faster than 3, 2 or 1 fully connected layers. But they perform poorly due to overfitting.
- LSTM models converged the fastest (in less than 5K iterations), yet they over-fitted. They also tend to perform better on moving objects rather than still ones. ALOV++ provides approximately 6500 training sequences which is relatively small for larger networks like LSTMs and fully connected layers.
Results
White: Ground Truth. Green: Our Model. Red: GOTURN's Trained Model.
The sequence of videos would show the result of benchmarking both trackers against the VOT2014 dataset. The bounding boxes resulted from official VOT toolkit.
Poster

References
- [1]D. Held, S. Thrun, and S. Savarese, “Learning to track at 100 fps with deep regression networks,” in European Conference on Computer Vision, 2016, pp. 749–765.
- [2]M. Kristan et al., “The Visual Object Tracking VOT2014 challenge results.” 2014 [Online]. Available at: http://www.votchallenge.net/vot2014/program.html