Projects

Pixel-wise Skin Segmentation
A tensorflow-based skin segmentation code. We perform skin segmentation based on the pixel values of an image. We train a Guassian Mixture of Models for skin and non-skin values and use that to classify image pixels (i.e. Skin or Non-Skin).
AUC Distracted Driver Dataset
The distracted driver posture classification dataset was inspired by StateFarm's Distracted Driver compeition on Kaggle. It consists of ten postures to be detected: safe driving, texting using right hand, talking on the phone using right hand, texting using left hand, talking on the phone using left hand, operating the radio, drinking, reaching behind, doing hair and makeup, and talking to passenger.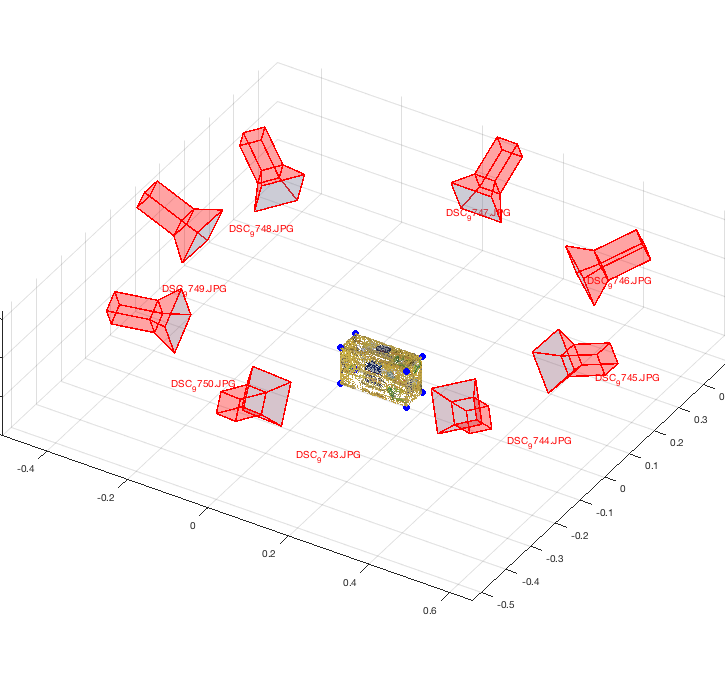
2D-3D Correspondences-based Model Construction
Given a 3D Model for a box, we want to re-construct the model from multiple images that captures the model from different angles. First, we build a list of 2D-3D correspondances per image. After that, we estimate the camera pose per image. Then, we project the 2D point onto the 3D model from each image (using the estimated camera pose) to re-construct the 3D model. Eventually, we shall use the constructed models to detect the object in variant poses and occlusions in different images using SIFT-based feature matching.
Object Detection: Histogram Of Gradients and Random Forest
A simple/classical object detection pipeline for three classes. We propose regions (i.e. windows) using selective search. For each window, we extracted features using Histogram of Oriented Gradients (HOG). Finally, we used random forests to classify those windows and give them confidence. Finally, Non-Maximum Suppression (NMS) is applied. We used OpenCV and C++.
DeepTracking: Real-Time Object Tracking
DeepTracking is a comprehensive study in which we demonstrate the effects of different architectures on the original GOTURN model. The tracker’s objective is to understand shape, motion, appearance changes of objects over variant periods of time, and keep track of the object location throughout a sequence of frames. To achieve that, we have lots of factors (i.e. accuracy, robustness, runtime/fps, memory footprint, training time) to fine-tune to reach the optimal objective.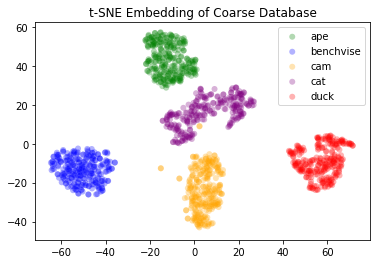
Realtime Neural Object Recognition and 3D Pose Estimation
Object Recongition and 3D Pose Estimation are heavily researched topics in Computer Vision. They are often needed in emerging Robotics and Augmented Reality applications. Most common pose estimation methods use single classifier per object, and thus, resulting in a linear growth of complexity with every new object in the environment. In this project, I use a custom hinge-based loss to learn descriptor that separate objects based on their class and 3D pose. Learned feature space will be used in combination with k-nearest neighbour to detect object class and estimate its pose.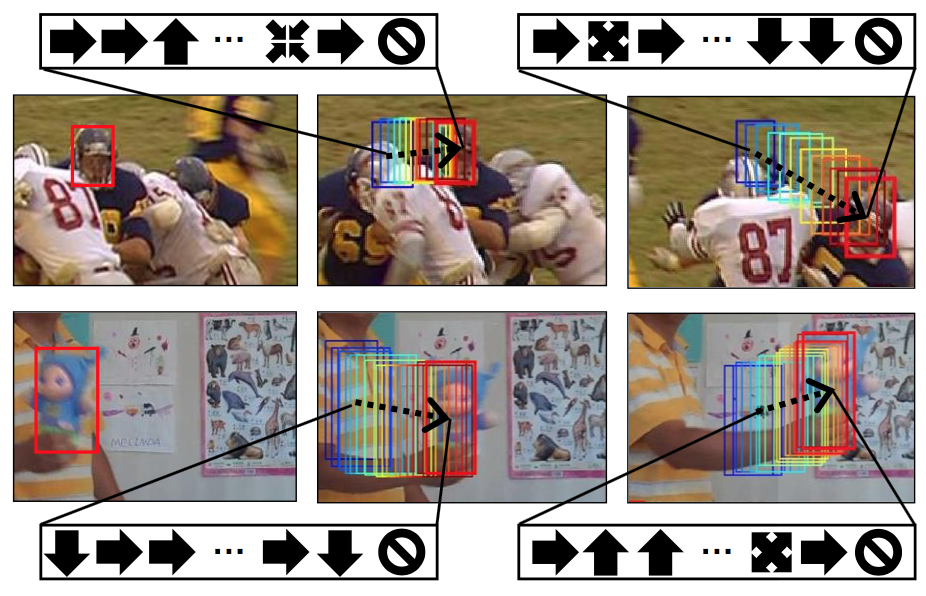
ADNet: Action-based Object Tracking using Reinforcement Learning
Deep networks introduce a prohibitive computational overhead that prevents their use in realtime applications. In this article, we discuss a newly proposed Action-Decision Network (ADNet) that improves accuracy and robustness and reduces computational overhead. The network uses a convolutional neural network as a feature extractor. Fully connected layers are used to predict a sequence of actions to obtain the target object's location. These layers are trained using supervised and reinforcement learning. Action-based tracking proves to be more computationally efficient.
#ResearchOps: Running Containerized OpenPose
Running machine learning experiments involve a considerable overhead of setting up GPUs, getting environments to work as expected, poorly documented code, conflicting package versions, and the list goes on. In an attempt to relieve the problem, I started containerizing most of my workflows. In this article, I describe how to run OpenPose pain-free on Docker.
Exporting Apple CoreML models using Keras and Docker
Apple devices could be used to host machine learning models. In this article, we are interested in the deployment of deep learning models on Apple devices. While there are many online references on the matter, there seems to be little resources on getting the correct CoreML models from an existing Keras model. In this article, I present a docker image where model exports are simple and have no dependency conflicts.